반응형
최대우도추정법(Maximum Likelihood Estimation)
- 데이터를 바탕으로 모델의 파라미터를 추정하는 방법
- 데이터가 특정 확률 분포에서 생성됨을 가정
이때, 파라미터를 조정하여 데이터가 생성될 확률(우도, likelihood)이
최대가 되는 파라미터 값을 찾는 것이 목표
말로는 이해가 잘 안되는듯해서
동전 던지기 예제로 알아보도록 해요
앞면이 나올 확률이 0.5입니다.
동전 던지기의 결과는 두가지 결과가 나오는 이항 실험(binary experiment)
이기 때문에 베르누이 분포로 모델링 할 수 있습니다.
이때 베르누이 분포에서는 성공 확률 p를 모수(parameter) 로 사용하고
p의 추정값을 구하기 위해서 최대우도추정법을 적용할 수 있습니다.
뭔가 끼워 맞추기 식이 아닌가...?
여튼, 데이터가 발생할 확률을 구하고 모두 곱한 값이 최대가 되도록
모델 파라미터를 조종하는 방법이다 ~!

0.86이란 값이 나왔는데 이게 유의미 한지를 판단하려면 검정이 필요합니다.
신뢰구간 검정을 통해서 파악해보도록 하겠습니다
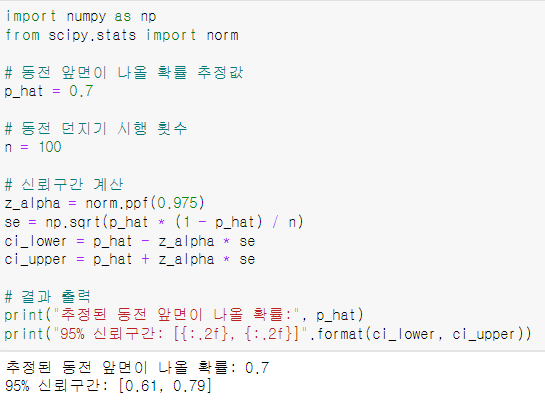
95%의 신뢰구간 안에 있는지를 파악해보았는데
한참 벗어난 수치입니다.
이러한 경우 모형이 잘못되었거나 계산 식에 문제가 있음을 파악할 수 있습니다.
..
..
..
여튼, 데이터가 발생할 확률을 구하고 모두 곱한 값이 최대가 되도록
모델 파라미터를 조종하는 방법이다 ~!
반응형
'통계학 > 검정에 대한 고찰' 카테고리의 다른 글
| #3. 가설검정 (0) | 2023.03.17 |
|---|---|
| #2. 평균, 분산 (0) | 2020.10.26 |
| #1. 표 (0) | 2020.10.19 |
| #0. 통계학 입장 (1) | 2020.10.19 |